Lab 4
Extracting the Remaining Service—Goodbye Monolith!
At this stage, our migration to serverless SaaS is well underway. We have introduced onboarding, identity, and a model that supports side-by-side support for our new multi-tenant microservices and the existing monolith. For many organizations, this represents a key stage in their migration. Having created a microservice and demonstrated that this two-pronged approach can work, you can now focus your energy on carving out more and more services until the monolith is no longer needed.
In a real-world scenario, this transition would be a somewhat involved process where you would need to invest significant time to slowly migrate your business logic and data to a microservices model. However, we’ve limited the functionality of our sample monolith here and want to demonstrate what it would look like to migrate the remaining bits of functionality and completely eliminate the need for the monolith application tier.
To make extract the final bit of functionality out of our monolith, we’ll need to move the product service out to a standalone microservice. This will mimic much of what we discussed above. However, now that we have multiple microservices, we will also need to think about what it will mean to have code and concepts that are common to both of our microservices. We’ll also look at another data partitioning model for this service, having our data represented in a relational database that can store data for all tenants in a shared construct (using what we call a “pool“ model).
The architecture at this stage is much simpler. Gone is the need to provision full monolith stacks each time a tenant onboards. Instead, our tenants now all share the serverless microservices that can scale on their own and do not require separate provisioning for each tenant. The diagram below provides a high-level view of the new architecture:
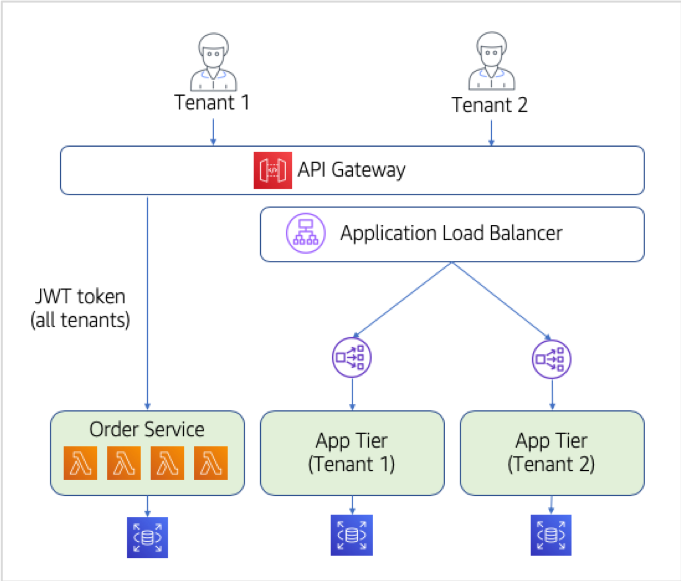
This diagram represents the completion of our migration process, highlighting that the functionality of our system is now supported by an API Gateway and two logical microservices (which are a composite of multiple Lambda functions).
What You’ll Be Building
The lab is all about getting your solution moved away from the monolith. The basic elements of making this final migration are as follows:
- Now that we have a second service, we can see that we need some way to extract and share core concepts that span our services. In the universe of serverless, we can achieve this through the use of Lambda layers. We’ll look at how we can move logging, metrics, and token management to a layer that can be deployed and versioned separately.
- We’ll extract our last service from the monolith, the product service. This service will mostly move in the same fashion as our prior order service. Once we have this all wired and aligned with our new layers, we will deploy the new product service and deploy the Lambda fucntions for this service.
- Once we have these common concepts in our layers, we’ll want to go back to our product and order services and add the instrumentation to use the code in these layers. We’ll update our logging and and add some metrics instrumentation to illustrate how these new mechanisms remove all awareness of tenant context from developers.
- As part of moving our service over, we also have to consider how we want to represent the product data. In this case, we’ll use a “pool“ model for the data where the tables in our relational database will hold the data for all tenant in a shared construct. A column in the table will be used to shard the data by tenant identifier.
Once these basic steps are completed, we’ll have the core elements of our migration completed. We’ll also have layers in place that will simplify the introduction of new services as we move forward.