Serverless Database
As part of moving to this new microservice, we also had to remove our dependency on the database monolith where orders had previously been shared in one large database used by all services. Extracting this data from the monolith is essential to our microservices story. Each of our microservices must own the data that it manages to limit coupling and enable autonomy. When we move this data out of the monolith, it also gives us the opportunity to determine what service and multi-tenant storage strategy will best fit the multi-tenant requirements of our microservice.
In this case, we’re looking at how we want to represent our order data that will be managed by our order management microservice. Should we silo the data for each tenant? Should it be pooled (share a common table/database)? What are its isolation requirements? These are all questions we need to answer. For this solution, we’ve decided to move the order data to DynamoDB and use a NoSQL representation. However, for isolation reasons, we’ve opted to put the data in separate tables for each tenant. Below is a conceptual model of the data representation for the order service:
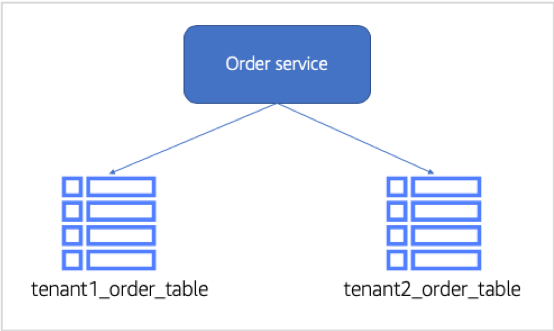
To see this in action, let’s now go look at the data that was added via our new order microservice. Navigate to the DynamoDB service in the AWS console and select the “Tables“ item from the navigation pane on the left. This will display a list of DynamoDB tables, including any tables for any tenant that have orders. Below is a sample that includes a few tenants table that were created:
Here you’ll see that there are two tables here, one for each tenant in our system. Your list of tables will vary based on the tenants you’ve introduced.