Microservices Transformation
Carving Out Our First Multi-Tenant Serverless Microservice
Now that we have an automated onboarding process and multi-tenant identity in place, we can start to focus more of our energy on decomposing our monolith into multi-tenant microservices. Our goal here is to carve out individual services from our monolith, slowly extracting the functionality from the monolith, enabling us to operate in a model where some of our application remains in the monolith while other bits of it are running as true multi-tenant serverless microservices.
A key part of this strategy is to support a routing scheme that enables side-by-side execution of the microservice and monolith services. The idea here is that we will have a single unified API for our services that will then route traffic to the appropriate target service (a Lambda function or an entry point in our monolith). The following diagram provides a conceptual view of the approach we’ll be taking to carving out this first service.
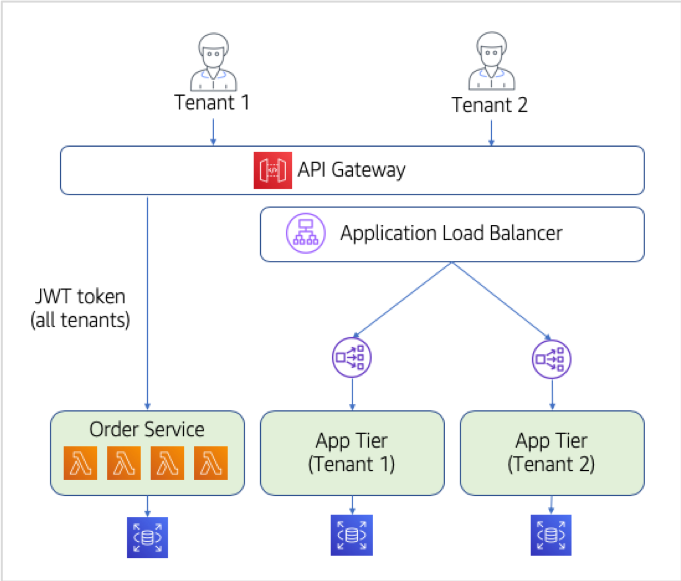
In this diagram, you’ll notice now that we have two separate paths for our tenants. As tenants enter the API Gateway, they can either be routed to our new Order service. Or, they can be routed to the monolith application tier. It’s important to note that the flows will be different if you are consuming the new microservices (Lambda functions) or the application tier. Since our Order service is a multi-tenant service, it will process requests for all tenants. Meanwhile, the monolith will still require a separate deployment for each tenant. It will also require the routing rules to direct traffic to the appropriate application tier (using Application Load Balancer routing rules).
Our goal for this lab, then, is to enable the conceptual view you see above. We’ll introduce and deploy our new multi-tenant Order services in a serverless model. We’ve stayed with Java here as the language or the individual functions of our Order service. However, you could imagine that a migration to a serverless might also involve a switch in languages. There are a wide range of factors that could influence your choice. For this exercise, though, it seemed to make sense to stick with one language to make it easier to follow the transition from monolith to serverless.
Generally, as we’ve broken services out of our monolith, we’re trying to create a class file that represents a logical microservice. The idea here is that we’ll still have a class with the different functions of our solution. These methods of our class will be deployed as individual Lambda functions. This model makes it easy for us to move our code over from the monolith without major changes. However, this is only the case because we already had a clear notion of services in our monolith. In many cases, the monolith will not break apart so cleanly. We also have to begin to leverage the tenant context that flows into this service, using it to partition data, add logging context, and so on.
We should note that this migration will not dig into the details of the data migration aspects of this problem. While these are an important part of the broader migration story, they are considered out of scope for this effort. So, as we carve out our new services and introduce new multi-tenant storage constructs, we’ll be starting with a blank slate (leaving whatever data exists behind in the monolith database).
What You’ll Be Building
This lab is all about getting our first service carved out of our application tier. We’ll focus on looking at what it means to build a serverless version of this service. This also means looking into how the service is deployed and configured within our infrastructure to support the model described above. The following is a breakdown of the key elements of the lab:
- Our first step will be to actually create the Lambda functions that makeup our Order service. We’ll review how our Java gets converted to a function-based approach and describe the basic exercise of getting these new functions deployed.
- The API Gateway will also require changes to support our new functions (along with the monolith tier). We’ll look at how the API Gateway will route specific Order service calls to the Lambda functions in our service and connect the dots between the development experience and the run-time environment.
- As part of extracting the order service, we must also think about how our data will be represented in a multi-tenant model. More specifically, we’ll need to pick a storage technology that best fits the isolation, performance, and scale needs of the Order service and introduce a data partitioning scheme.
Upon completion of these steps, you should be on your way to your full serverless SaaS model. With one service migrated, you can now begin to think about how you would carve out the remaining services from the application tier.